
Machine Translation
Contents
Machine Translation#
Machine translation (MT) is a sub-field of computational linguistics that investigates the use of software to translate text from one language to another. Machine Translation has a long history that dates back to the 50’s of the past century when the first computational experiments to automatize the complex process of translation started (to explore the history of MT, see for example [Hutchins, 1995]).
In the past, the main approaches to MT were rule-based, which basically means that linguistic rules such as grammar, vocabulary, etc. were encoded into a program and that the program was using them to perform the translation; statistical, which means that the MT engine tries to generate translations using statistical methods based on bilingual text corpora; or hybrid, combining the statistical and the rule-based approach. While the improvements of such systems were slow but remarkable over the decades, quality still remained limited.
It is only with the application of the new paradigm of artificial intelligence, namely neural networks, to machine translation in 2014 (the first paper to apply it was [Cho et al., 2014]), and with the scaling of this technology into production by Google in 2016 (read Google’s blog entry announcing this breakthrough) that the quality of MT increased exponentially. It was the beginning of Neural Machine Translation (NMT).
Neural machine translation is based on the ability of a neural network to encode a piece of text in one language, commonly a sentence, into a mathematical representation. This abstract representation of the sentence is able to capture, at least partially, also its meaning and represent an intermediate state of the text, something that can be seen as a kind of (mathematical) interlingua. This intermediate representation is then decoded by another neural network into a new sequence of symbols (words) in the target language.
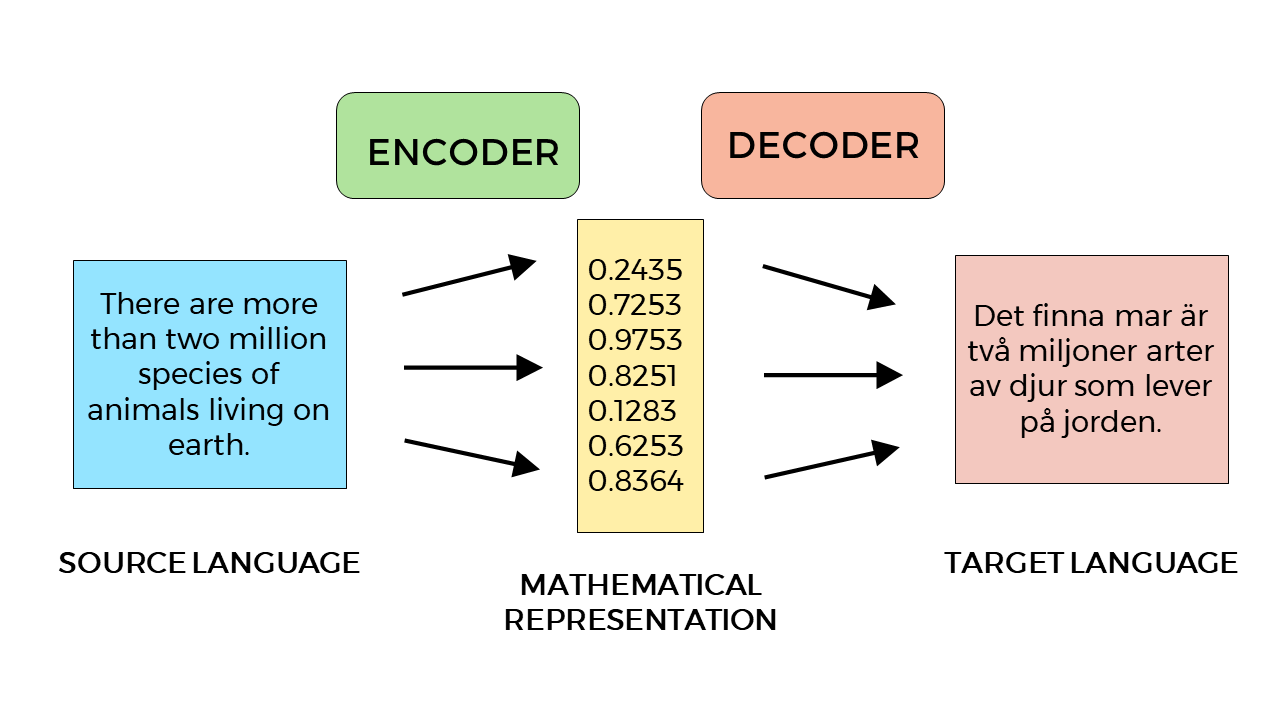
Interestingly, the first neural network, the so-called encoder, is only able to translate the sentence in language A to that abstract representation (formally a set of features) while the second one, the so-called decoder, is only able to translate that representation back to a text into language B. Both have no idea about each other, and each of them knows only its own language. This very popular architecture takes the name of encoder-decoder model and the most known type of neural networks used is the so-called recurrent neural networks (RNN). It has to be noted that there are many flavors of architecture. The field is still evolving.
What is remarkable about NMT (as with any application based on neural networks, especially deep learning) is that the system learns to perform a task without being explicitly programmed to do so. A NMT system, for example, learns to harmonize gender and case in different languages without anyone teaching it to do so. The learning process happens by exposing the network to an abundance of examples. In the case of the encoder-decoder system introduced above, the models are jointly trained to maximize the conditional probability of a target text given a source text.
Different from rules-based and statistical systems, NMT has also the advantage of being able to translate between language pairs that the system has never seen before. This is possible because of the intermediate representation of text introduced before. In this sense, direct translation between languages with no сommon dictionary is possible.
While NMT has reached human parity in some scenarios (for a discussion about human parity in machine translation, see this blog post from Slator, 2018), NMT is not as flexible and powerful as human-crafted translations. This is especially true when not only the linguistic but also the communicative aspects of translation are taken into consideration.
One of the limitations of MT is that a machine does not translate considering aspects like culture, context, communicative intentions, etc. This is out of the scope of language models. In reality, the source language is processed at the linguistic level. Among the several other challenges faced by MT we find disambiguation, i.e. the ability to find a suitable translation when a word can have more than one meaning, and the use of non-standard or figurative language. Because these and other aspects of the translation process require knowledge that is not available to machines, MT is intrinsically limited in the quality that can be achieved. In order to perform the next step in quality, and make MT really similar to humans, new paradigm shifts in AI will need to happen.
Bibliography#
- 1
W. John Hutchins. Machine translation: A brief history. In E.F.K. Koerner and R.E. Asher, editors, Concise history of the language sciences, pages 431–445. Pergamon, Amsterdam, 1995.
- 2
Kyunghyun Cho, Bart van Merrienboer, Çaglar Gülçehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. CoRR, 2014.
Further reading#
Read Google’s blog entry announcing the application of neural networks in Google Translate: A Neural Network for Machine Translation, at Production Scale
Read IBM’s press release from 1954 announcing the first machine translation demonstration: Russian was translated into English by an electronic “brain” today for the first time
Compare human and machine translation abilities here: Human Parity Achieved’ in Machine Translation — Unpacking Microsoft’s Claim