
What is NLP
Contents
What is NLP#
Natural Language Processing (NLP) is a discipline in computer science that aims at automating the manipulation of natural language to achieve some specific goals and to enable computers to make some sense of human language in both written and verbal form. NLP has been around for 50 years or so, bringing about many everyday applications such as word spelling correctors, and the like. Lately, NLP has been deeply influenced by machine learning and deep learning advancements so that most NLP applications are nowadays based on ML. From elementary components, such as tokenization, stemming, part-of-speech tagging, dependency grammar, etc., to complete applications, such as machine translation, summarization, autocompletion etc., NLP makes use of large quantities of language data to create general language models, such as BERT [Devlin et al., 2019] or GPT-3 [Brown et al., 2020]. Such models are mathematical representations of a language that can be used to perform several tasks and be integrated in higher-level pipelines, for example automatic speech recognition and machine translation. Computer-assisted interpreting (CAI) tools make abundant use of NLP, for example to match terminology in a digital boothmate, to translate terminologies, etc.
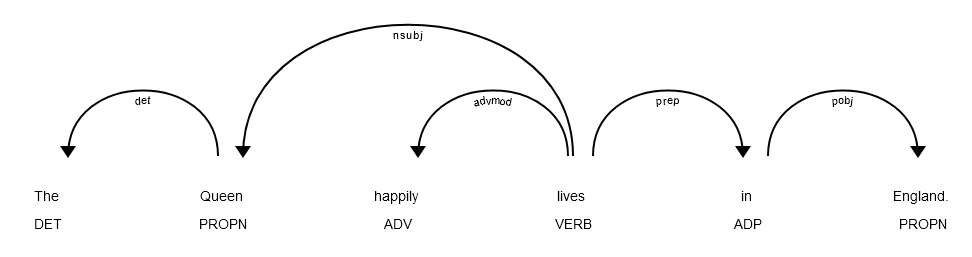
Fig. 1 Parsed example sentence in the form of a dependency tree using spaCy#
Natural Language Understanding#
Natural Language Understanding (NLU) is a subfield of natural language processing that aims at allowing machines to develop some sort of understanding of the language and the communication process. They do this by using syntactic and semantic analysis of text and speech to determine the meaning of a sentence or of a text. In some cases, NLU establishes a relevant ontology: a data structure which specifies the relationships between words and phrases, disambiguating homonymies, etc.
From a linguistic and a philosophical point of view, it is very difficult to define what NLU is [Bender and Koller, 2020]. This leads in many cases to confusion about the extent of ‘understanding’ that a system reveals. Famous intelligent systems such as IBM’s Watson, that won in 2011 the Jeopardy game against humans, do not possess, for example, any capability of “understanding”, at least in the sense that is intuitively defined by humans, even less any sign of “intelligence”. However, this is not a limitation for many applications built on top of NLP and NLU, since it is clear by now that many smart systems can be built without the need for the machine to manifest any intelligence [Floridi, 2014]. Modern speech transcription systems, for example, can reach an impressive low Word Error Rate, even surpassing human transcribers, just by means of Deep Learning, hence statistical processing. In the context of interpretation, NLP/NLU can be used to produce a translation of a speech, to match terminology in a digital boothmate, to extract Named Entities, such as proper names, organisations, etc.
Natural Language Generation#
Natural Language Generation (NLG) is another subfield of natural language processing. While natural language understanding focuses on computer understanding and comprehension, natural language generation enables computers to produce language, typically in writing. In more technical terms, NLG is the process of producing a human language text response based on some data input. This text can also be converted into a speech format through text-to-speech synthesis. NLG can be used by CAI-tools to produce a summary of a speech while maintaining, at least to some degree, the integrity of the information, for example. In this case, the input is an unfinished or a previous speech to get an idea of what has been said before. While this kind of text summarization produces new text, there are other ways not based on NLG, which instead aim to find the most important sentences in the text and just repeat them.
Bibliography#
- 1
Luciano Floridi. The 4th Revolution: How the infosphere is reshaping human reality. Oxford University Press, 2014.
- 2
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. ArXiv, 2019.
- 3
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, T. J. Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeff Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. ArXiv, 2020.
- 4
Emily M. Bender and Alexander Koller. Climbing towards NLU: On meaning, form, and understanding in the age of data. In Proceedings of the 58th annual meeting of the association for computational linguistics, 5185–5198. Association for Computational Linguistics, July 2020.
Further reading#
Discover IBM’s Watson: https://www.ibm.com/ibm/history/ibm100/us/en/icons/watson/
Explore spaCy’s dependency trees: https://explosion.ai/demos/displacy
And spaCy in general: https://spacy.io/