
Multimodal Machine Learning
Contents
Multimodal Machine Learning#
Multimodal machine learning, i.e. the process of learning representations from different types of modalities (images, text, audio, etc.), has recently gained in popularity. The promise is to allow artificial intelligence to better solve problems that require the combination of several types of information.
Humans do this all the time: the most natural way to make sense of the world is, in fact, to extract and analyze information from diverse sources, and combine them into something meaningful. One reason why humans can understand speech better than AI is that we use not just our ears but also our eyes. When we listen to a person speaking, for example, we create meaning not only from what the person is saying (the words), but also from the gestures she is using, the tone of her voice, the setting in which she finds herself, and so forth. Yet, until recently, AI has been treating different information channels as separate areas without many ways to benefit from each other. With the expansion of multimedia, researchers have started exploring the possibility to use several data types, for example audio and video, to achieve one result, for example to transcribe audio in a more precise way.
Let’s take the example of speech recognition. In 2022, Meta AI published a new framework called AV-HuBERT [Shi et al., 2022, Shi et al., 2022]to improve automatic speech transcription thanks to lips monitoring, de facto combining Speech with Vision, two of the traditional areas of Artificial Intelligence. Incorporating data on both visual lip movement and spoken language, projects such as AV-HuBERT aims at bringing artificial assistants closer to human-level speech perception (see META AI blog post), improving transcription also in less-than-optimal conditions, for example with overlapping speeches. Anyone who has ever dealt with a voice assistant would be pleased with any improvement in this user experience.
In this graph, you can see the lower Word Error Rate of this model reported by the authors by the same amount of training data (on the right), or the still very low error rate using a fraction of training data (in the middle). This means that combining different source of information not only has the potential to improve accuracy, but also to reduce the amount of data that is needed to train a model.
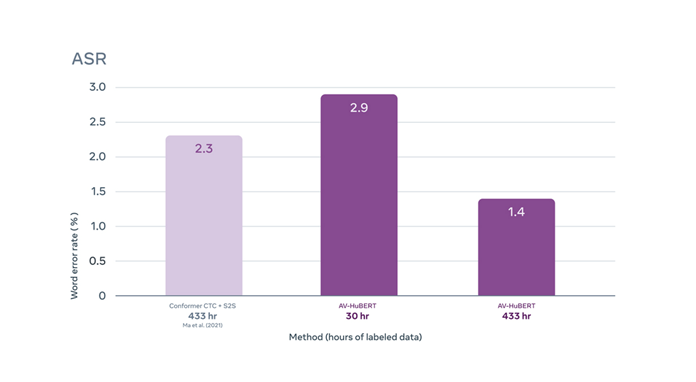
How does this approach work? While traditional speech recognition engines are trained using audio files and their transcriptions, a multimodal framework like AV-HuBERT uses video recordings to perform the same task. The model is trained with both the audio and the transcriptions (as in classical speech recognition) as well as the video that corresponds to that audio and transcription. By combining visual information, such as the movement of the lips when speaking (video) along with auditory clues (audio), such models are able to capture precise associations between the two input channels, which leads, according to the authors, to an improved final transcription.
In simultaneous speech translation, i.e. the translation of a continuous input text stream into another language with the lowest latency and highest quality possible, the translation has to start with an incomplete source text, which is read progressively. This is a challenge for a machine. Seminal projects are trying to integrate speech and visual inputs to compensate for missing source context in the unfolding speech (see [Caglayan et al., 2020]). In this paper, the authors seek to understand whether the addition of visual information can compensate for this missing source context, and report a slight increase in translation quality.
Bibliography#
- 1
Bowen Shi, Wei-Ning Hsu, and Abdelrahman Mohamed. Robust self-supervised audio-visual speech recognition. CoRR, 2022.
- 2
Bowen Shi, Wei-Ning Hsu, Kushal Lakhotia, and Abdelrahman Mohamed. Learning audio-visual speech representation by masked multimodal cluster prediction. ArXiv, 2022.
- 3
Ozan Caglayan, Julia Ive, Veneta Haralampieva, Pranava Madhyastha, Loïc Barrault, and Lucia Specia. Simultaneous machine translation with visual context. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), 2350–2361. Association for Computational Linguistics, 2020. tex.timestamp: Wed, 23 Sep 2020 15:51:46 +0200.
Further reading#
Meta AI: https://ai.facebook.com/blog/ai-that-understands-speech-by-looking-as-well-as-hearing/